

How Do I Fix Crawled Currently Not Indexed Error?
- Mar 13, 2022
- 6 min read
If you're looking at your Google Search Console exclusions list, you might be wondering why you have some pages excluded due to the error Crawled - currently not indexed. This might seem alarming because all of our SEO efforts are meant to have our pages indexed.
So, how do I fix crawled currently not indexed error? The most common cause for this error is that Google simply didn't think that your content was valuable enough to index. This means that you may need to add more unique content, add internal links or check for duplicate content, etc.
There can be several different reasons for this error, and we will breakdown how to fix them below. Some of these fixes will be simple and others will take a little more effort. However, before we can fix this error, we need to fully understand what it means.
What does Crawled - Currently Not Indexed Mean on Google Search Console?
Pages are excluded from indexing for various reasons, including: the pages are duplicates of indexed pages, blocked from indexing by something on your site, or for a reason that causes Google to think there is an error.
According to Google's support article, here is exactly what Google says this exclusion reason means.
The page was crawled by Google, but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling. ~ Google Search Console Help
While this sounds a little scary and like there is not very much hope that the URL will ever be indexed, don't be discouraged. It's important to understand that just because one or more of your page links has this exclusion reason, doesn't mean that it can't be resolved or eventually indexed. Instead of doing nothing, let's take this as an opportunity to see how we can improve the content of the page so that it can be indexed.
So naturally, the next question is, what can we do to remove this exclusion reason and have the page indexed?
How to Fix Crawled - Currently Not Indexed Step-by Step
Disclaimer: I am going to use my own website as an example here, but I cannot guarantee any results or promise that following these steps will for sure get your page index. There could be other factors on your website that are affecting the indexing which are not addressed in this article.
While writing this article, I decided to check my own Google Search Console and found that I have a handful of articles with the status Crawled - currently not indexed. I thought it would be the perfect opportunity to use one of my own URLs as an example of how I would attempt to remove this exclusion error and get the URL indexed.
Therefore, below, I will show you exactly what I am going to do to make sure my page is optimized and ready to be indexed by Google. I'll be looking at the highlighted article below called, How to Change URL Without Losing SEO
One of the reasons why Google may not index could because there is a technical error on the site. This could be anything from a 500 internal server error, 404 error on the page, robots.txt is blocking the page, etc.
Another reason could be because of the content itself. The content isn't unique enough, needs more internal links, is duplicate of other content on the site, etc.
Therefore, the first thing I want to do is a full analysis of the site on both a technical and on-page level. Let's start with the technical side:
Technical Page Analysis
One of the easiest ways to see if there is a technical error to have Google check for you! This is one of my favorite tools within Google Search Console. It's the Inspect URL tool.
To get to it, when you hover your mouse over the URL you want to check, you'll see a magnifying glass. Click this to go to the Inspect URL page.

Once you're on the inspect URL page, you'll find a lot of useful information and tools.
The first thing you might notice is that my URL is affected by the index exclusion Crawled - currently not indexed. You'll also see the last crawled date. This date is only 3 days prior to writing this article. If the date was more than two weeks ago, I would say that you maybe want to simply request indexing and wait and see if the issue has resolved itself.
Since there are no real apparent errors on this screen, I am going to click on Test Live URL and see if we get any errors there.

Running a live site test will allow you to troubleshoot a missing page from Google's index and determine what you need to do to fix it. You can read more about what different results from the live test might mean here.
Below are the results from my URL. This is what I was hoping to find. Basically, the response is URL is available to Google. There are no technical reasons why Google cannot access the page.
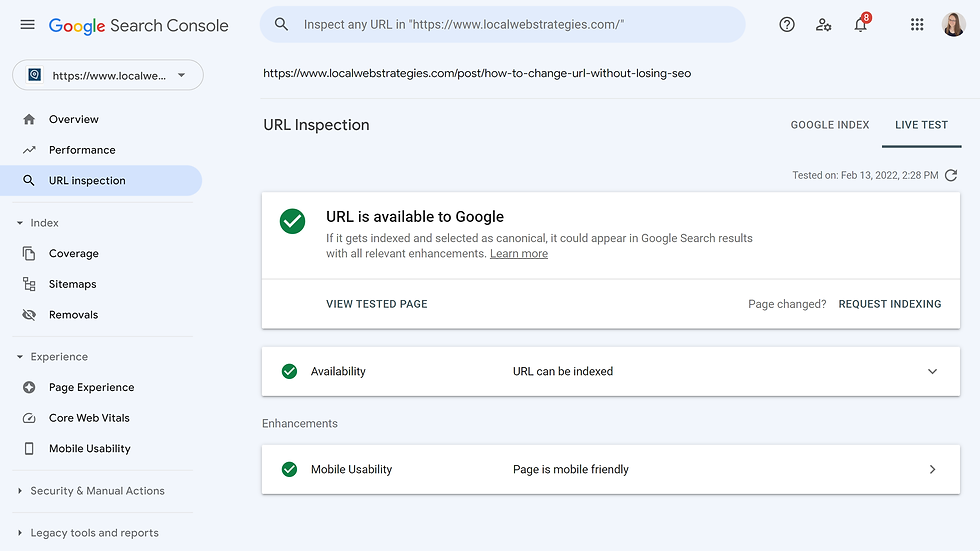
Even though I've already determined that there are no technical errors, I am also going to check my robots.txt to make sure that there is nothing there blocking the site from being indexed. If this were the case, it should have shown up in the Live Test on Google Search Console, but for the sake of this article I am going to check it anyway.
In order to see your robots.txt file, you simply need to type in your domain with /robots.txt at the end. What is robots.txt for? Basically, it tells crawlers what they are and are not allowed to crawl.
A robots. txt file tells search engine crawlers which URLs the crawler can access on your site. ~ Google Search Central
Google Search Console provides another great tool that allows you to test your Robots.txt to see if a specific user agent (or crawler) can access your site or if it's being blocked.
Since we are trying to get the page indexed on Google, we want to make sure that googlebot is not blocked. To test this, go to the robots.txt Tester, select your property/website, add the URL you want to check at the bottom, make sure googlebot is selected as the user agent, and click the red Test button.
If everything is good, you should see that the URL is Allowed and there are no errors, like this:
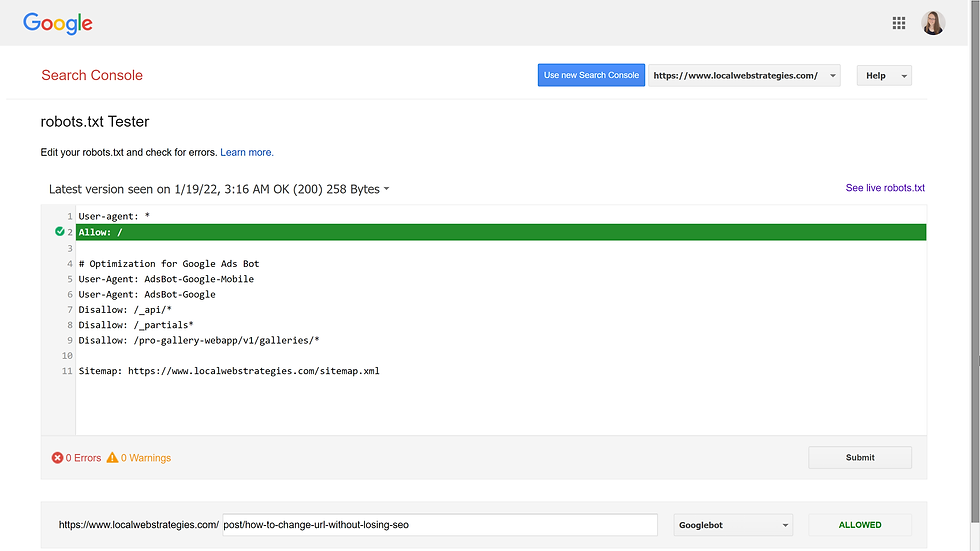
Now that the technical analysis is complete, lets move on to the on-page analysis!
On-Page Analysis
What do I mean by "on-page"? This is where I want to analyze the content itself. We know that technically, everything looks great, so the exclusion reason must be for something on the content side.
First, I want to do a basic on-page SEO analysis, which basically looks like this:
What is the word count? There are a lot of opinions in the SEO community around how long your content should be. I believe that there is no set number. The length of your content should be relative to the amount of competition you have. If your website platform does not give you the word count of your article, you can use WordCounter.net (copy/paste your content into the site and it will automatically count the words).
The article we're looking at has ~1000 words. When I check Google for my main keyword, "how to change url without losing seo", there are 7 other blog articles with an average word count of ~1800. I could increase my word count with relevant content.
How many H2s do I have? A little-known fact about SEO is that Google is looking at more than just your title. Google scans your page in the same way that a reader would in order to find out what your article is about. The H2s on your page are a good indication to Google regarding the topic of your site. The more you have, the more information Google can get.
I currently have four H2s on the article: Why are 301 redirects important for SEO? , How to Setup a 301 Redirect on Wix, How to Setup a 301 Redirect on WordPress, How to Setup a 301 Redirect on Squarespace & Shopify. By adding more content to the page, I can add more descriptive H2s to the site.
I'm I utilizing keywords? Google can tell if my article is not something their users would be interested in or searching for. Therefore, it's important to use keywords that Google Searchers would actually use. Some of my favorite ways to do this is by looking at the Google auto suggested keywords (start typing the Google search bar and see what Google suggests for other keywords. I also love the Keywords Everywhere chrome extension which will give you keyword ideas in addition to the estimated month search volume.
My main keyword, "how to change url without losing seo", is a Google autosuggest keyword and also has an estimated 40 searches per month. However, I only used the keyword once in the article outside of the title.
How relevant is the content to the main topic? One of the first things that Google looks at when they analyze a page is the H1 (title) of your page. This is what they expect the article to be about. Your content should align with the title. It is easy to take your article in many different directions and get a little off topic, but this could hurt you in the end.
While my entire article revolves around creating 301 redirects in order to prevent your SEO from being lost after changing your URL, I think I may have confused Google with the step by set instructions on how to set up 301 redirects on various platforms. I should add more content to the post to talk about the effect of 301 redirects (or the lack thereof) on site SEO.



















Comments